
Teaching Computers to Speak English
How does ChatGPT summarizes and generates text so flawlessly? How do language models actually work? This post is for you.

ChatGPT has such a strong command over the English language that people are using it to edit, summarize and write content because it writes better than they do #guilty-as-charged 👀. But how did ChatGPT achieve this level of mastery? How is it able to read, write, and even code so well? The answer lies in language models, a type of machine learning model that excels at predicting words based on the context. Some of the most well-known language models are GPT-4 and BERT, the models that power Chat-GPT and Google Search respectively.
In this post, I explore how language models are trained to make computers literate in any language, whether it's English, Javascript, or Spanish. I take two passes at explaining the training process. In the first pass, I give a high-level overview of the training process. In the second pass, I go deeper into the technical details by explaining how gradient descent and backpropagation are used in neural networks. By the end, I hope readers have a better understanding of how Chat-GPT is able to speak like us. If you are new to machine learning it might help to read this article I wrote that simplifies some of the key machine learning concepts.
High Level First Pass: Finding Patterns in Data Through Masking
The first step in training any machine learning model is getting relevant data. For language models, this is real-world sentences. A great source for this is the internet — an oasis of free text that can be easily scraped. If you are training a large language model (LLM), then you need a lot of training text. GPT-3 was trained on roughly half a trillion words, equivalent to 10,000 years of continuous speech if you speak at 100 words per minute. That is more English than most humans see in their lifetime which explains why Chat-GPT has such a robust understanding of English.
After collecting the data, we want our model to generalize patterns about sentences so that it “learns” the language. One way to understand and speak a language is to be able to accurately predict the next word given the previous context. If a model is able to predict the next word again and again, it ends up generating meaningful content. For example, if you input the word "robot" into ChatGPT, it generates an essay about robots by predicting the next suitable word, one word at a time. With this insight, the problem of modeling language is simplified to predicting the next best word.

The standard method to teach a model to predict the next best word is to remove one word from a real sentence and have the model guess what the missing word is. Based on how close the model's guess is to the right answer, the model is tweaked. This process is repeated on all the training examples until the model can almost always predict the right word.
To explain this process again, but more precisely. First, initialize the model parameters to random values. Then, repeat the following steps:
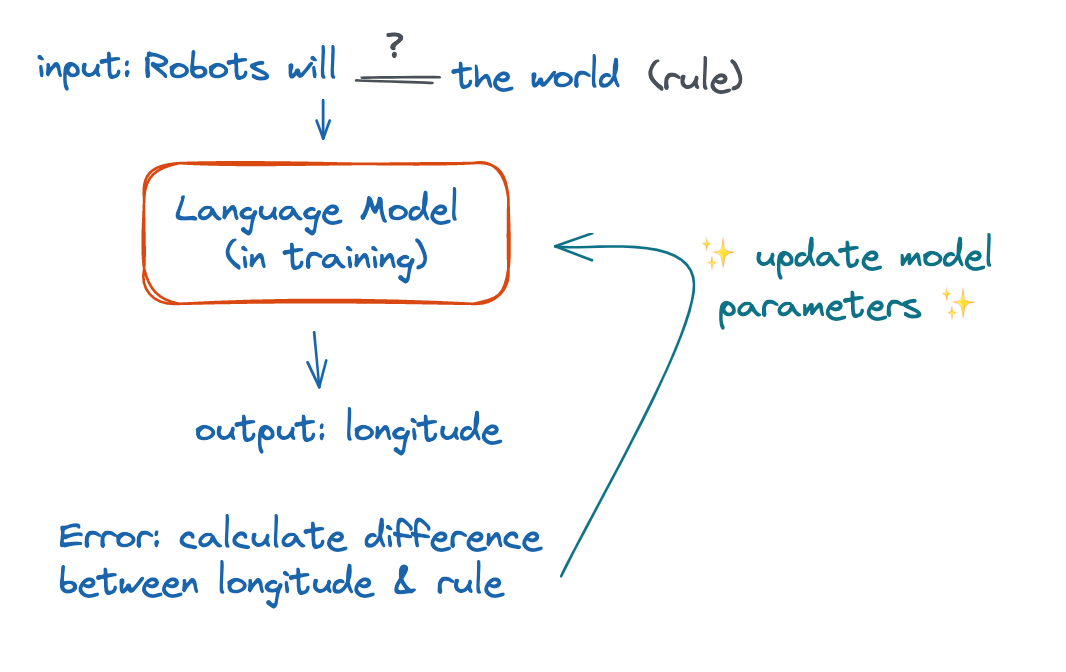
Take a real sentence and remove a word, a process called masking. In the example above, mask the word “rule” from the sentence Robots will rule the world.
Feed the masked sentence to the model and ask the model to predict what the missing word is.
Since the model is still in training, its predicted output will be wrong. Calculate the error between the predicted missing word and the right word in the original sentence using an error function. An example error function could be the mean square error between the two embedded words.
Send the error value back to the model. In the example,
longitudeandrulemean totally different things so it’s a bad prediction and the error will be high.Update the model’s parameters to optimize for a lower error. That way, when the model comes across this example in the future, the prediction will be more right.
Repeat again and again on millions of examples until the final parameter values ensure that the model almost always spits out an acceptable next word.
In essence, training a language model involves getting a computer to get good at guessing masked words. The model gets good by having the right set of parameter values. Hence, the parameter values are the meat of a model and they represent what the model has learned. For example, GPT-3's 175 billion parameters encode information about the probability distribution and statistical relationship between text used on the internet.
At this point, I have given a high-level description of how language models learn. In the next section, I go deeper into the technical details of how a model’s parameter values are updated based on the error (step 5). Researchers cannot manually choose parameter values and hope that it decreases the error. Instead, the gradient descent algorithm along with backpropagation is responsible for updating the parameter values based on the error.
Technical Second Pass: Finding the Best Parameters with Gradient Descent and Backpropagation
Part 1: Gradient Descent Algorithm — Finding the Minimum of the Cost Function
The fundamental idea behind the gradient descent algorithm is to minimize the function that represents the average error across all the training data. By finding the parameters (i.e., weights) that minimize this error, we have a model that will predict a sensible next word given the context.
To visualize this, let's take a look at the graph below. The graph represents the loss or error of a model that has two weights. At the absolute minimum of this graph, the average error is very low. With these weight values, the model would be good at guessing the masked words in the training data. Further, the hope is that when the model is used on new, unseen data, it will perform equally well by predicting sensible next words. Hence, we want to find what the weight values are at this point on the graph.

Unfortunately, there is no computationally-efficient algorithm to find the absolute minimum of a complex function like this. Therefore, we need to settle for finding local minimums instead. The gradient descent algorithm helps find the local minimum of the cost function.
To illustrate how the gradient descent algorithm works, let’s perform it on the two-weight model above. Initially, we have no idea what the ideal model weights should be, so we randomly initialize their values. This puts us at some random point on the graph above and we want to get to some local minimum. Then, repeat the following steps as a part of the gradient descent:
At the current weight values, calculate the average error. Do this by running the model on all the training data and averaging the error.
At this point, we want to know how we should tweak the weight values to decrease the average error and get closer to a minimum. In the graph above, should we move right, left, or diagonal?
To figure out how to tweak the weights, take the gradient (slope) at the current point. Then, modify the weights proportional to the negative gradient. A negative gradient implies that the error is going down, so we want to move in that direction. Further, if the gradient is large (the graph is steep) it means we are far from a local minimum so we want to modify the weights by a large amount. And vice versa when the gradient is small.
Repeat steps 1-3 at the new weight values until the error no longer decreases, implying that we’re at a minimum.
In one sentence, gradient descent is just about tweaking each weight in the model to reduce the error for the training data. Further, the algorithm is just three steps:
Find the average error for the training data at some weights.
Compute the gradient at that point.
Take a step in the direction of the negative gradient. The size of this step is proportional to the gradient.
At this point, you might be wondering how we compute the gradient mentioned in step 2. The is answered by backpropagation.
Part 2: Backpropagation — Finding the Gradient to Find the Minimum
Rather than getting into the calculus in backpropagation, this section aims to visually explain backpropagation: the algorithm to compute the gradient at certain weights.
Backpropagation is best explained by an example. Suppose you have the phrase “Robots will save” and you mask the word save, but your neural network model predicts the next word is destroy instead, like so:

Then we would want to propagate the error between destroy and save back through the network from the output layer in order to correct the weight values so that it performs better next time. In the diagram above, ideally, save and destroy would have had a probability of 1 and 0 respectively. This means that we need to change the weight values so that destroy‘s final node value (or activation) goes from 0.8 to 0. How would we do this?
A node’s activation value is equal to the weighted activation of all incoming nodes. For example, in the diagram below, A5’s activation is the weighted total of A3 and A4’s activations. In order to drive A5’s activation closer to 0, we would need to change w3, w4, and A3 and A4. To change A3, however, we would need to change w1, w2, A1, A2. And in order to change A1, we would need to change the weights in its previous layer. This is how the term backpropagation was coined: in order to change the final activation values, we need to pass the error backward and update the weights in all previous layers of the model.

Further, we want to nudge the weights in proportion to how much we want to adjust the activation of each node. We do this for each node in the output layer, getting a list of nudges to all the weights.
This tells us how one training example wishes to nudge each one of those weights. If we only listened to that, however, the model would over-optimize for that example. Hence, we run the backpropagation algorithm for every other training data example and average these desired tweaks across all the examples. This final value is equivalent to the negative gradient of the cost function. Further, once we have this gradient, we tweak the weights by it in the gradient descent, getting us closer to a local minimum.
TLDR Conclusion
In summary, language models learn languages by getting good at predicting the next word given some previous words. They are good this because the model has parameter values that optimize for a low error when predicting masked words on the training data. These parameter values are chosen by descending down the error function until we reach weight values at a local minimum via the gradient descent algorithm. Further, backpropogaton updates all the weights in a model based on the error in a training example.
I hope this post was helpful. Subscribe if you are interested in having more posts like this sent to your inbox. If you have any feedback or corrections, send them my way. If you have any questions, leave a comment. And if you think anyone else would appreciate this post, kindly share it with them.
Huge thank you to Shyamoli Sanghi and Paul Wilkins, both of whom hold Masters in Machine Learning and graciously fact-checked this post.
Really nice post ! Love how digestible some of the technically heavy topics are:
- do you think focusing on optimizing masking can lead to improved outputs ?
- if I wanted to create an LLM better than GPT-4 what component would you recommend focusing on optimizing ?
You Are amazing and can explain complex stuff really well. Saw your podcast att pragmatic engineer and was really impresswd by you. Keep it up and keep inspiring and sharing knowledge to the world. More great things will come your way.